Deep Dive Into Large Language Models
By Vikram S. Negi on May 02, 2025
The following is a summary of the things I learned in a course created by Andrej Karpathy on YouTube. This is by far the most detailed yet easy to follow teachings of how Large Language Models (LLMs) work.
Pre-Training
In this step we download and pre-process text data downloaded from the internet. We would like to have a corpus of high quality text from publicly available data sources.
Points to note about the text dataset:
- High quantity - scaling law.
- High quality - reputable sources.
- High diversity - larger knowledge base for model.
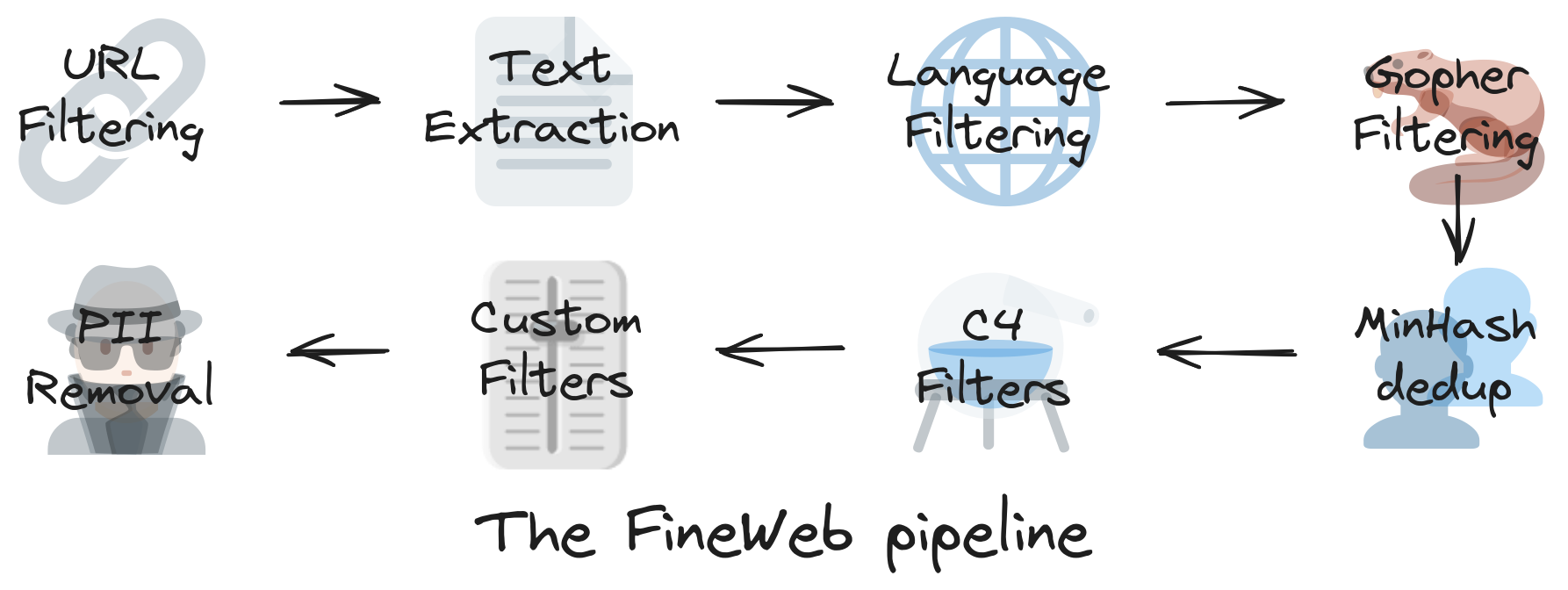
To find more information about pre-training, please check out the FineWeb documentation.
Neural Nets expect a one-dimensional sequence of symbols and a finite set of symbols (tokens). The set of symbols represent the possible outputs for the model.
Tokenization
The main reason we tokenize the stream of characters to numbers is so that a Neural Net is able to understand them better. There is an underlying representation of characters eg. UTF-8 encoding.
We would like to achieve a balance, in possible symbol size and the resulting sequence length. We prefer more symbols and shorter sequences. Why? Compression is comprehension, it leads a LLM to understand more information in a limited context window.
To visualize how LLMs tokenize text, check out tiktokenizer.
Here is an example of tokenization process shared in the lecture:
- Convert each character in a text string to
UTF-8encoding (binary) - Take each 8-bit character and convert them to to bytes (reduces to 256 possible characters)
- Use byte-pair encoding algorithm (each pair becomes a new token)
- The previous step can be repeated (this gives us a shorter sequence of string with a larger vocabulary)

Note: Current LLMs typically use vocabulary of ~100,000 tokens.
Neural Network Training
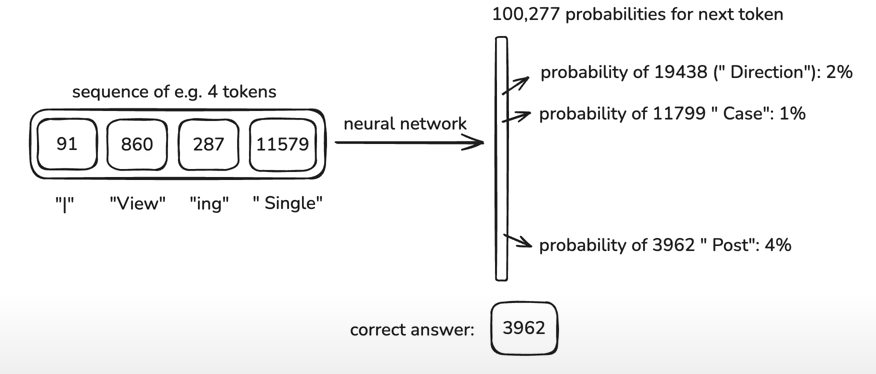
Training a neural network takes the most amount of compute resources. Also, the max input dimensions (tokens) of the network is decided arbitrarily, eg. 8,000 token (context) window. The input to the neural net is called the context. In simple words we are solving a multi-class classification problem with the labels being the token vocabulary.
The input to the network can be of variable length from 0 to max context window. And the output of the network is a probabilistic distribution of the tokens.
Training a neural network means to update the probability distribution to conform to the training data. In every iteration of training, we update the probabilities of the distribution of the possible tokens (~100,000 tokens). We are trying to nudge the model to guess the next output token.
Neural Network Internals
A neural net may have billions of parameters, called as weights and biases. These values are tuned or adjusted during the training phase of the model. If the prediction is incorrect the weights are adjusted.
A model is nothing but a mathematical function parameterized by the weights of the model and takes an input of a fixed size. Note that each token has a vector representation also called as an embedding. This vector is of a fixed dimension.
Visit the LLM Visualization website to understand the network architecture used in LLMs.
Inference
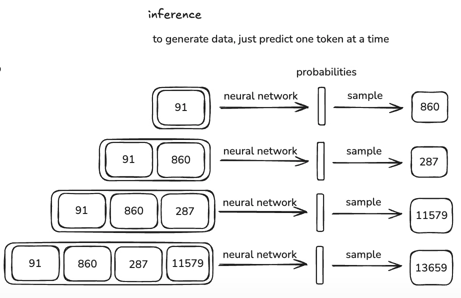
Given some input tokens, the model samples a token from the output probability distirbution. The tokens with higher probability have a higher chance of being sampled.
These systems are stochastic or probabilistic in nature and therefore their outputs are unpredictation and random. After repeating the next token prediction till some point, the output string can be thought as remixes or the original training data or being inspired by it.
Base Model
Training these next token prediction models requires a lot of resources. For example to train GPT-2 we require eight H100 GPUs. Unfortunately, this cannot be done locally on your system.
Base model is an internet text token simulator and not an assistant that helps answer the user's questions. Think of it like a token autocomplete.
In the task of predicting the next token for the sequence of context tokens, the model has "learned" a lot about the world. And the knowledge is stored in the parameters of the mode. The model has the capability to recongnize patterns from the input token sequence.
Think of the model parameters as a lossy compression of data from the internet.
Another interesting phenomenon is the ability for the base model to learn from the context tokens. This is also called few-shot learning. Here we can nudge the base model into answering our questions with providing more context to it.
We can create a translator program by constructing a few-shot prompt and leveraging in-context learning ability of the base model.
The following prompt shows the in-context learning ability of a base model:
Human: Hi there! Who are you?
Assistant: Hello, I'm your AI Assistant. I'm here to help answer questions...
Human: How does photosynthesis work?
Assistant: Photosynthesis is the process by which green plants, algae...
Human: Why is the sky blue?
Here the model picks up the context and completes the conversation between a human and an assistant.